■ seaborn
- matplotlib의 성능 및 디자인을 업그레이드
- Pandas의 DataFrame을 대상으로 시각화 한다.
- EDA(Exploring Data Analysis) 작업에 많이 사용
- URL : http://seaborn.pydata.org
seaborn: statistical data visualization — seaborn 0.13.0 documentation
seaborn: statistical data visualization
seaborn.pydata.org
■ 실습 데이터셋 확인
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터셋 준비
# seaborn 데이터셋 위치 : https://github.com/mwaskom/seaborn-data
df = sns.load_dataset('mpg') # DataFrame 객체로 데이터셋 반환
display(df.head(10)) # head() : DataFrame의 상위 5개 데이터를 불러온다
print(df.shape) # (398, 9) 행과 열 값, 레코드와 컬럼 값
# 데이터 요약본
df.info()
# object type은 명목형, 범주형<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 392 non-null float64
4 weight 398 non-null int64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null object
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
# 기술통계 확인하기
df.describe() # 수치형 컬럼에 대해서만 기술통계값 출력
df.describe(include='object')
df['origin'].value_counts() # origin 컬럼에 있는 고유값별 레코드 개수origin
usa 249
japan 79
europe 70
Name: count, dtype: int64
■ 관계형 그래프
▶relplot()
- 변수간의 상관성을 시각화 하는 그래프
- 매개변수 kind='scatter' 또는 kind='line'을 통해서 그래프의 종류를 선택할 수 있고, 매개변수를 지정하지 않으면 'scatter'가 기본으로 적용된다.
- hue 매개변수를 통해 범주형 데이터별 포인트의 색깔을 다르게 지정할 수 있다.
sns.relplot(data=df, x='weight', y='mpg', kind='scatter', hue='origin') # 제조 국가별 연비와 무게
plt.show()
sns.relplot(data=df, x='weight', y='mpg', kind='scatter', col='origin')
plt.show()
▶ regplot()
- 선형회귀선을 추가적으로 그린다
- y = wx + b : 선형회귀식, w=기울기, b=절편
sns.regplot(data=df, x='weight', y='mpg', marker='+')
plt.show()
▶ lmplot()
- 데이터의 산점도와 함께 선형회귀 모델 적합을 플롯팅 한다.
sns.lmplot(data=df, x='weight', y='mpg', col='origin', truncate=False) # 전체 구간을 맞춰줌
plt.show()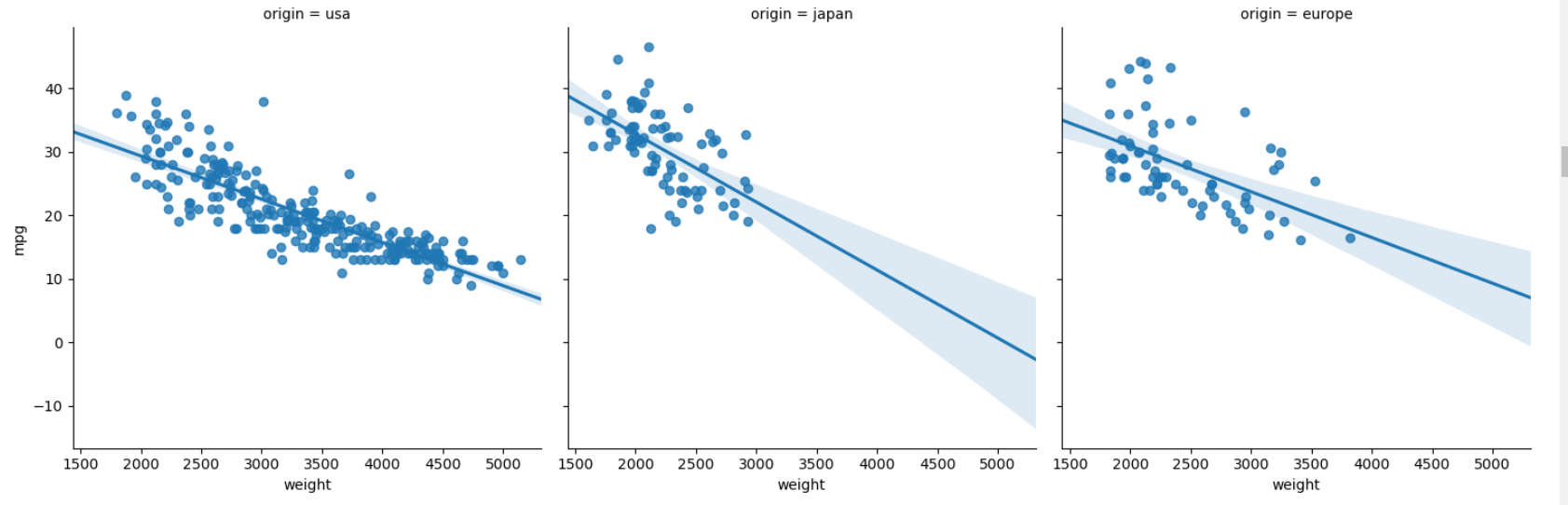
▶ pairplot()
- 각 변수들의 분포와 모든 변수들간의 분포 관계를 보여준다.
- 시간이 오래 걸린다. 따라서 원하는 컬럼만 추출해서 그리는 경우가 많다.
- vars : 보고싶은 컬럼명을 리스트로 전달
sns.pairplot(data=df, hue='origin')
plt.show()
▶ lineplot()
- 연속형 데이터들에 대한 관계를 보여주는데 적합한 그래프
- lineplot은 기본적으로 그래프를 그리기 전에 x값을 기준으로 데이터를 정렬하고 그래프를 그린다.
- 같은 x값에 대해 여러 개의 y값을 갖는 경우에 각 x값에 대한 평균과 95%의 실뢰구간을 평균 위주로 표시한다.
sns.lineplot(data=df, x='model_year', y='mpg')
plt.show()
▶ heatmap()
- 데이터의 상관관계 정도에 따라 색차이를 부여한 그래프
iris = sns.load_dataset('iris')
iris.head()
# iris : 꽃받침의 길이와 넓이, 꽃잎의 길이와 넓이, 품종
iris['species'].value_counts()species
setosa 50
versicolor 50
virginica 50
Name: count, dtype: int64
iris.pivot_table(index='species')#, aggfunc=['mean', 'min', 'max'])
# 지정된 컬럼이 행의 값으로, 나머지는 열의 값으로 들어감 (평균값)
# aggfunc=[] : 집계함수
corr = iris.corr(numeric_only=True) # 각 컬럼별 상관계수 표시
corr
sns.heatmap(corr, annot=True) # 밝을수록 상관관계가 높음
plt.show()
# 꽃잎의 길이가 길면 너비도 넓다
■ 분포형 그래프
▶ histogram
- bins : 최소 최대값 사이 몇 칸으로 나눠서 그릴지 지정(데이터 구간의 개수)
sns.displot(data=df, x='mpg', bins=10) # 연비별 도수분포표, 10개 구간으로 나눔
plt.show()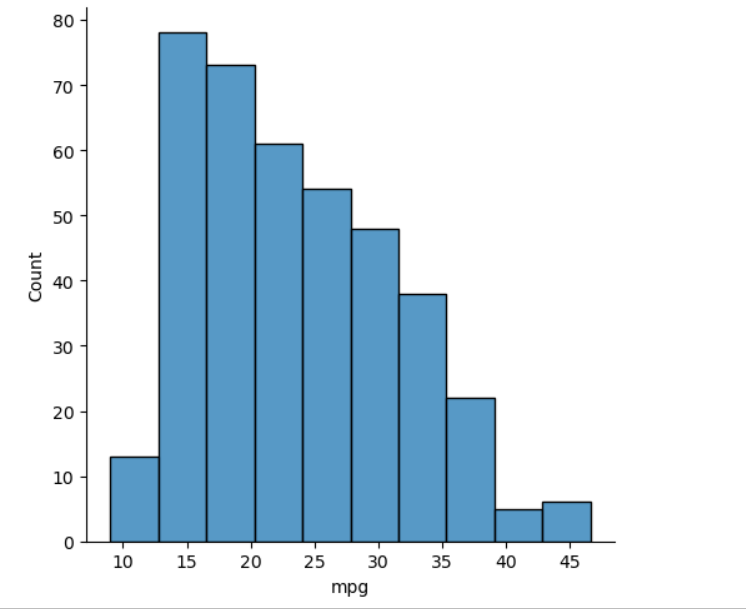
# y 파라미터만 지정하면 가로로 된 히스토그램을 그린다
sns.displot(data=df, binwidth=1, y='mpg')
plt.show()
▶ barplot()
- x축에는 범주형 변수, y축에는 연속형 변수를 입력
- x에 연속형, y에 범주형을 넣으면 수평막대그래프를 그린다.
- estimator에 집계함수 이름을 지정한다.
- 평균(기본값, np.mean), 합(np.sum), count(len), 중앙값(np.median), 표준편차(np.std)
# style 종류 : default, ggplot, classic, bmh, whitegrid
plt.style.use('default')sns.barplot(data=df, x='origin', y='horsepower', estimator='median') # 제조 국가별 마력
plt.show()
▶ boxplot()
sns.set_style('whitegrid') # 선을 그어줌
sns.boxplot(data=df, x='origin', y='mpg') # 국가별 연비
plt.show()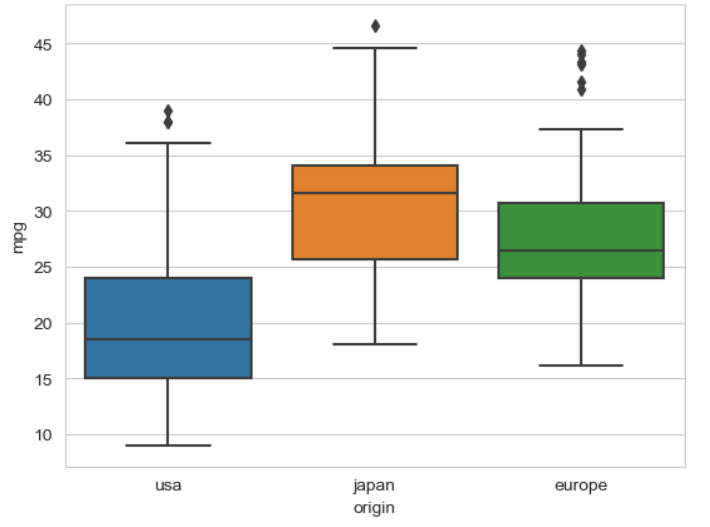
▶ violinplot()
- 데이터의 분포에 따라 통통하고 홀쭉하게 표현한 모습이 바이올린을 닮은 그래프
- boxplot은 이상치를 한 눈에 파악할 수 있고, violinplot은 데이터의 분포를 한 눈에 파악하는 데 용이하다.
sns.violinplot(data=df, x='origin', y='mpg')
plt.show()
'데이터 분석 > 시각화' 카테고리의 다른 글
| [시각화] matplotlib (1) | 2023.11.03 |
|---|---|
| [시각화] matplotlib - 선 그리기 (0) | 2023.11.03 |