[Numpy] 배열 생성
■ Numpy 개요
- URL : https://numpy.org
- Numerical Python의 약자
- 고성능의 수치 해석용 Python library
- Numpy는 데이터 사이언스 분야에 있어서 기초가 되는 라이브러리로써, Pandas, Matplotlib, Scikit-learn, Tensorflow 등 다른 라이브러리들에서 자주 사용된다.
- Numpy 그 자체만으로는 높은 수준의 데이터 분석 기능을 제공하지 않지만, Python 상에서 Numpy를 활용해 데이터를 표현하고 다룰 줄 알아야만 조금 더 고차원적인 데이터 분석을 구현할 수 있다.
Numpy는 고성능 다차원 배열과 행렬 연산에 필요한 함수와 툴을 제공
- 대규모의 다차원 배열과 행렬 연산에 필요한 다양한 함수를 제공
- matrix와 vector와 같은 array 연산에 최적화
- 다양한 matrix를 프로그래밍으로 표현하고 계산을 위해 효율적인 방법이 필요
- Python은 Interpreter 언어이기 때문에 데이터가 커지고, list를 이용하여 matrix 연산을 할 경우 연산 처리속도가 느리고, 복잡하다.
- 메모리 버퍼에 배열 데이터를 저장하고 처리하는 효율적인 인터페이스를 제공
- 파이썬 list 객체를 개선한 Numpy의 ndarrayy(N-Dimensional Array) 객체를 사용하면 더 많은 데이터를 더 빠르게 처리할 수 있다.
■ Python 다차원 배열의 이해
▶ 숫자 자료형
# 세 명의 학생의 수학과목 점수를 설정
math1 = 11
math2 = 12
math3 = 13# 합과 평균 구하기
total = math1 + math2 + math3
average = total / 3
print(f'수학점수 합:{total}')
print(f'수학점수 평균:{average:.2f}')
# 수학점수 합:36
# 수학점수 평균:12.00
▶ 리스트 자료형
math_list = [11, 12, 13]
# 새로운 학생의 수학점수 추가
math_list.append(14)
total = 0
average = 0
# 합
for math in math_list:
total += math
# 평균
average = total / len(math_list)
print(f'수학점수 합:{total}')
print(f'수학점수 평균:{average:.2f}')
# 수학점수 합:50
# 수학점수 평균:12.50
- 그런데 만약 시험문제에 오류가 발견되어 모든 학생의 점수를 1점씩 올려줘야 하는 상황이 발생한다면 어떻게 처리해야 할까?
# list comprehension 사용
math_list = [math + 1 for math in math_list]
print(math_list)
# [12, 13, 14, 15]
# 각 반별로 구조가 확장되면 이중리스트의 형태로 만들어야 함
■ Numpy로 구현한 다차원 배열
- Numpy를 사용하면 중첩된 자료구조를 효율적으로 다룰 수 있다.
- import numpy as np 형태로 사용하는 것이 일반적이다.
import numpy as np
# 파이썬의 리스트를 Numpy의 다차원으로 변환
math_ndarray = np.array([[11, 12, 13], [21, 22, 23], [31, 32, 33]])
print(math_ndarray)
print(type(math_ndarray)) # 다차원 배열이라고 부른다
# [[11 12 13]
# [21 22 23]
# [31 32 33]]
# <class 'numpy.ndarray'># 각 원소에 1을 더하려면...
new_ndarray = math_ndarray + 1
print(new_ndarray)
# for문을 사용하지 않고도 모든 원소에 1이 더해짐
# [[12 13 14]
# [22 23 24]
# [32 33 34]]
- 전체 합 구하기
# 전체 합 구하기
np.sum(math_ndarray) # 198
- 전체 평균 구하기
# 전체 평균 구하기
np.mean(math_ndarray) # 22.0
- 행의 평균 구하기
# 행의 평균 구하기 (반별 평균)
np.mean(math_ndarray, axis=1) # 축 옵션=1
# array([12., 22., 32.])
- 열의 평균 구하기
# 열의 평균 구하기
np.mean(math_ndarray, axis=0) # 축 옵션=0
# array([21., 22., 23.])
■ Numpy의 axis(축) 정리
- 행렬의 모양을 다음과 같이 확인할 수 있다.
- ndarray.shape
- 1차원 벡터 : (원소개수, )
- 2차원 행렬 : (행, 열)
- 3차원 행렬 : (깊이, 행, 열)
- shape의 결과 값을 기준으로 axis 값이 0부터 부여된다.
- 2차원 (행, 열)인 경우 axis 값이 (0, 1)이먀 axis=0은 행, axis=1은 열을 나타낸다.
- 3차원 (깊이, 행, 열)인 경우 axis 값이 (0, 1, 2)이먀 axis=0은 깊이, axis=1은 행, axis=2는 열을 나타낸다.

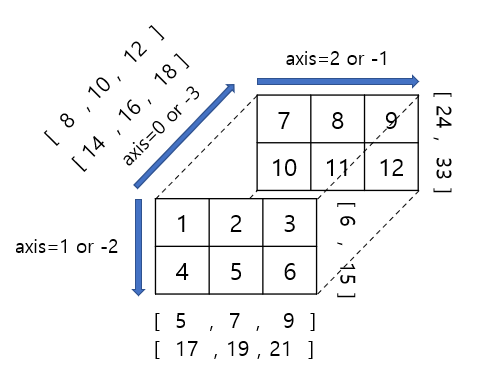
import numpy as np
array1 = np.array([[1,2],[3,4]])
print(array1)
print(array1.shape) # (2, 2)
print('-'*20)
array2 = np.array([[[1,2,3],
[4,5,6]],
[[7,8,9],
[10,11,12]]])
print(array2)
print(array2.shape) # (2, 2, 3) 2행 3열이 2개[[1 2]
[3 4]]
(2, 2)
--------------------
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
(2, 2, 3)
print('2차원 배열의 axis=0 기준 합: ', end='') # 행 기준 합
print(np.sum(array1, axis=0))2차원 배열의 axis=0 기준 합: [4 6]
print('2차원 배열의 axis=1 기준 합: ', end='') # 열 기준 합
print(np.sum(array1, axis=1))2차원 배열의 axis=1 기준 합: [3 7]
print('3차원 배열의 axis=0 기준 합: ') # 깊이 기준 합
print(np.sum(array2, axis=0))3차원 배열의 axis=0 기준 합:
[[ 8 10 12]
[14 16 18]]
print('3차원 배열의 axis=1 기준 합: ') # 행 기준 합
print(np.sum(array2, axis=1))3차원 배열의 axis=1 기준 합:
[[ 5 7 9]
[17 19 21]]
print('3차원 배열의 axis=2 기준 합: ') # 열 기준 합
print(np.sum(array2, axis=2))3차원 배열의 axis=2 기준 합:
[[ 6 15]
[24 33]]
■ Numpy 특징
▶ Python의 list가 느린 이유
- 파이썬의 리스트는 포인터의 배열이다.
- 따라서 각각의 객체가 메모리 여기저기에 흩어져 있다.
- 그러므로 캐시 활용이 어렵다.
▶ Numpy의 ndarray가 빠른 이유
- 타입을 명시하여 원소의 배열로 데이터를 유지한다.
- 다차원 데이터도 연속된 메모리 공간이 할당된다.

■ 배열 생성 - 1
▶ array()를 이용한 생성
- python의 list나 tuple을 이용해서 numpy의 ndarray를 생성한다.
- 다차원 배열의 모든 원소는 `동일한 데이터 타입`을 가져야 한다.
○ 정수형
- int64, int32(기본타입), int16, int8, uint64 형이 있다.
- int64 : -2^63 ~ 2^63-1 까지의 정수 표현
- uint64 : 0~2^64-1 까지의 정수 표현
intArray = np.array([[1,2],[3,4]])
print(intArray.dtype) # dtype 자료형 확인 : int32uintArray = np.array([[1,2],[3,4]], dtype='uint')
print(uintArray.dtype) # uint32
○ 실수형
- 실수형의 기본 타입은 'float64'
floatArray = np.array([[1.1,2.2],[3.3,4.4]])
print(floatArray.dtype) # float64
▶ 형변환
- 데이터가 정수로 입력되더라도 dtype의 값으로 실수형을 명시한다면 실수형으로 자동 형변환이 이루어진다.
a = np.array(['1', '2', 3, 4], dtype=np.float64)
print(a) # [1. 2. 3. 4.] 실수형으로 변환
print(type(a[0])) # <class 'numpy.float64'>
# copy 옵션의 사용
a = np.array([1,2,3,4])
# copy=False : 새로운 ndarray 생성이 아니라, 원본과 동일한 참조값을 받는 것이다. b = a 와 동일한 표현
b = np.array(a, copy=False)
# id : 참조값
print(a, id(a)) # [1 2 3 4] 2809826136528
print(b, id(b)) # [1 2 3 4] 2809826136528
▶ arange()를 이용한 생성
- 일련의 숫자를 만들기 위해 arange() 함수를 사용한다.
- 파이썬의 range() 함수와 비슷하다.
a = np.arange(1, 10) # end값은 포함하지 않음
print(a) # [1 2 3 4 5 6 7 8 9]
b = np.arange(10, 30, 5)
print(b) # [10 15 20 25]
# step 값으로 실수형도 사용할 수 있는 것이 range() 함수와의 가장 큰 차이
c = np.arange(0, 2, 0.3)
print(c) # [0. 0.3 0.6 0.9 1.2 1.5 1.8]
▶ Numpy 배열의 주요 속성들
1. ndarray.shape
- numpy 배열의 차원을 tuple 타입으로 반환
2. ndarray.dtype
- 배열의 자료형을 반환
3. ndarray.ndim
- dimension 차수를 정수로 반환 (1차원, 2차원, 3차원)
4. ndarray.size
- 배열의 요소의 총 개수를 정수 값으로 반환 (len()함수와 비슷)
a = np.arange(10)
print(a) # [0 1 2 3 4 5 6 7 8 9]
print(a.dtype) # int32
print(a.ndim) # 1차원
print(a.shape) # (10,)
print(a.size) # 10
■ 배열 생성 - 2
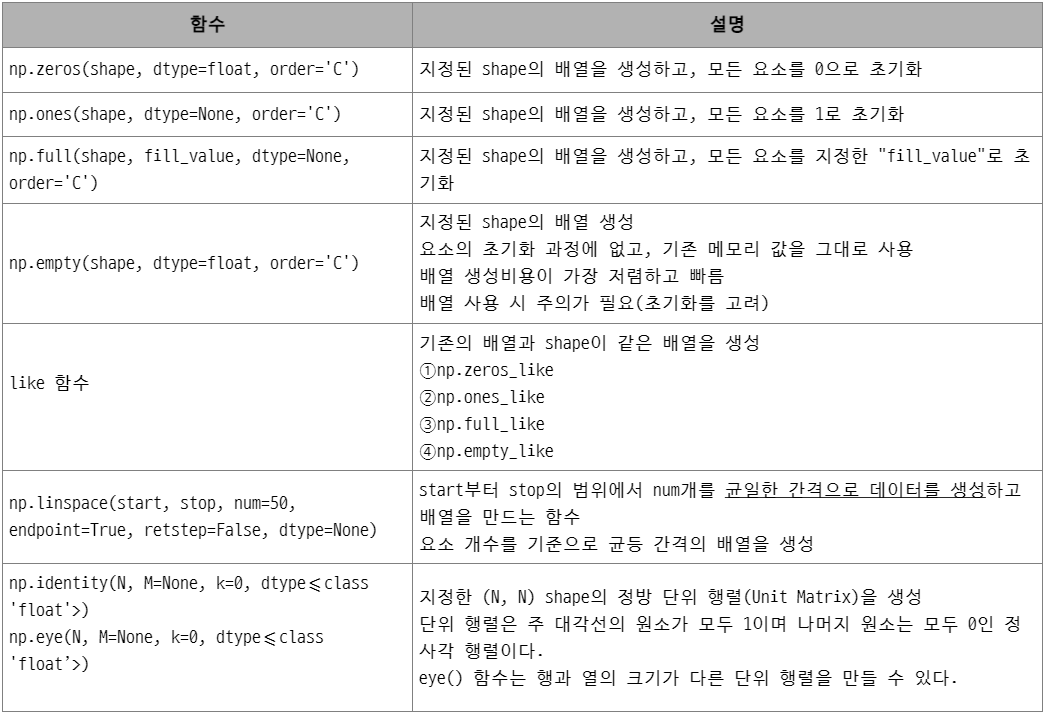
▶ np.zeros()
- 모든 요소가 0으로 이루어진 지정한 크기의 새로운 배열을 생성
a = np.zeros(4) # 원소 4개로 이루어진 1차원 백터
print(a) # [0. 0. 0. 0.] 실수형
a = np.zeros(4, dtype=int) # dtype=np.int32
print(a) # [0 0 0 0] 정수형
b = np.zeros((3,3)) # 3행3열
print(b)
# np.zeros_like(ndarray) : 지정된 배열과 같은 형태의 새로운 배열 생성
c = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(np.zeros_like(c)) # 동일한 형태의 배열로 0으로 채워짐[0 0 0 0]
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
[[0 0 0]
[0 0 0]
[0 0 0]]
a = np.array([True, False, False, True])
print(a.dtype) # bool
print(a) # [ True False False True]
▶ np.ones()
- 모든 요소가 1로 이루어진 지정한 크기의 새로운 배열을 생성
print(np.ones((2,3))) # 2행3열
print(np.ones_like(c)) # 3행3열[[1. 1. 1.]
[1. 1. 1.]]
[[1 1 1]
[1 1 1]
[1 1 1]]
▶ np.full()
- 지정한 크기에 입력한 원소를 전부 채운 배열을 생성
print(np.full((2,3), 2)) # 2로 채운 2행3열
print(np.full_like(c, 0.1, dtype=float)) # c는 정수형이기 때문에 실수형으로 변환[[2 2 2]
[2 2 2]]
[[0.1 0.1 0.1]
[0.1 0.1 0.1]
[0.1 0.1 0.1]]
[문제] 배열생성
- 1~10 사이의 값에 대해 다음의 조건에 맞는 2차원 배열을 생성하시오.
- 첫 번째 행은 역순으로 나열된 홀수 정수의 요소를 갖고, 두 번째 행은 짝수 정수의 요소를 갖는다.
a = np.array([np.arange(9, 0, -2), np.arange(2, 11, 2)])
print(a)[[ 9 7 5 3 1]
[ 2 4 6 8 10]]
■ 배열 생성 - 3
▶ np.linspace()
- start부터 stop의 범위에서 num개를 균일한 간격으로 데이터를 생성하여 배열을 만든다.
print(np.linspace(0, 2, 9)) # 0이상 2이하의 범위에서 9등분하여 요소들을 설정[0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. ]
x = np.linspace(0, np.pi * 2, 100)
y = np.sin(x)
import matplotlib.pyplot as plt
plt.plot(x, y)
plt.show()
▶ np.identity(), np.eye()
- 지정한 크기의 정방 단위 행렬을 생성
- 정방 단위 행렬은 주대각선의 원소가 모두 1이며, 나머지 원소는 모두 0인 정사각형 행렬이다.
- eye() 함수는 행과 열의 크기가 다른 단위 행렬도 만들 수 있다.
print(np.identity(2))
print(np.identity(3, dtype=int))
print('-'*30)
print(np.eye(3))
print(np.eye(3, 4))
print('-'*30)
# 세 번째 값이 1 : 대각선 인덱스를 의미, 기본값은 0
# 양수 값은 위쪽 대각선(열)의 위치 값
# 음수 값은 아래쪽 대각선(행)의 위치 값을 나타낸다
print(np.eye(3, 4, 1))
print(np.eye(3, 4, -1))[[1. 0.]
[0. 1.]]
[[1 0 0]
[0 1 0]
[0 0 1]]
------------------------------
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
------------------------------
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
[[0. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]]
■ 배열의 변경

▶ np.reshape() / ndarray.reshape()
- 원본을 변경하지 않고 배열을 새로운 shape으로 수정한다.
- 원본 배열의 요소의 개수와 변경할 모양의 배열 요소의 개수가 다르면 에러를 발생한다.
a = np.arange(6)
print(a) # [0 1 2 3 4 5]
b = a.reshape((3, 2)) # np.reshape(a, (3, 2))와 동일 : 3행2열의 2차원 배열
print(b)
print(a) # 원본 배열의 모양은 변하지 않는다
print('-'*30)
c = np.reshape(a, (1, 6)) # 1행6열의 2차원 배열
print(c)
print('-'*30)
d = np.reshape(a, (-1, 2)) # 열의 크기를 2로 맞추고, 행의 크기는 전체 요소 개수에 맞춰서 알아서 지정
print(d)
print('-'*30)
e = np.arange(1, 11).reshape(2,5) # 2행5열로 바로 바꿀 수도 있다
print(e)
f = e.reshape((-1, 2, 1)) # 2행1열로 맞추고, 깊이는 알아서 지정
print(f)
print('-'*30)
g = f.reshape(-1) # -1의 의미는 행열의 값이 없으므로 요소를 한 줄로 나타냄 (1차원 벡터)
print(g)[0 1 2 3 4 5]
[[0 1]
[2 3]
[4 5]]
[0 1 2 3 4 5]
------------------------------
[[0 1 2 3 4 5]]
------------------------------
[[0 1]
[2 3]
[4 5]]
------------------------------
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
[[[ 1]
[ 2]]
[[ 3]
[ 4]]
[[ 5]
[ 6]]
[[ 7]
[ 8]]
[[ 9]
[10]]]
------------------------------
[ 1 2 3 4 5 6 7 8 9 10]
▶ np.resize() / ndarray.resize()
- 원본 배열을 새로운 shape으로 수정한다.
- 대상 배열의 요소의 개수가 원래 배열과 동일하지 않으면 크기를 강제로 조정한다.
a = np.arange(12)
a.resize((3, 4))
print(a) # 원본의 모양을 변경한다
print('-'*30)
a.resize((4, 4)) # 원본과 크기가 달라도 오류가 발생하지 않는다
print(a) # 강제로 크기 조정 -> 0으로 채움[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
------------------------------
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[ 0 0 0 0]]
▶ ndarray.flatten() / ndarray.ravel()
- 배열을 1차원으로 만든다.
- flatten() 함수는 배열을 복사해서 1차원으로 변경한다. (즉, 원본에 영향을 미치지 않는다)
- ravel() 함수는 원본을 복사하는 것이 아니므로 메모리 낭비가 없다. (단, 값을 수정하면 원본도 수정된다)
a = np.arange(1, 5).reshape(2, 2)
print(a)
print(a.flatten()) # 다시 1차원으로 만든다[[1 2]
[3 4]]
[1 2 3 4]
a = np.arange(1, 5).reshape(2, 2)
r = a.ravel()
print(r)
a[1, 1] = 5
print(a)
print(r) # 원본 배열 변경의 영향을 받는다[1 2 3 4]
[[1 2]
[3 5]]
[1 2 3 5]
▶ np.expand_dims()
- 지정한 axis(축)의 위치에 다차원 배열의 차원을 늘려준다.
a = np.array([1, 2])
print(a)
print(a.shape)
print('-'*30)
# 1차원 벡터에 첫 번째 축(행 축)을 추가하여 2앞에 1이 추가되어 (1,2)의 모양으로 확장
b = np.expand_dims(a, axis=0)
print(b)
print(b.shape)
print('-'*30)
# 1차원 벡터에 두 번째 축(열 축)을 추가하여 2뒤에 1이 추가되어 (2,1)의 모양으로 확장
c = np.expand_dims(a, axis=1)
print(c)
print(c.shape)[1 2]
(2,)
------------------------------
[[1 2]]
(1, 2)
------------------------------
[[1]
[2]]
(2, 1)
a = np.arange(1, 7).reshape(2, 3)
print(a)
print(a.shape) # (2, 3)
print('-'*30)
# 2차원 행렬을 깊이 축(axis=0)으로 확장
b = np.expand_dims(a, axis=0)
print(b)
print(b.shape) # (1, 2, 3)
print('-'*30)
# 2차원 행렬을 행 축(axis=1)으로 확장
c = np.expand_dims(a, axis=1)
print(c)
print(c.shape) # (2, 1, 3)
print('-'*30)
# 2차원 행렬을 열 축(axis=2)으로 확장
d = np.expand_dims(a, axis=2)
print(d)
print(d.shape) # (2, 3, 1)[[1 2 3]
[4 5 6]]
(2, 3)
------------------------------
[[[1 2 3]
[4 5 6]]]
(1, 2, 3)
------------------------------
[[[1 2 3]]
[[4 5 6]]]
(2, 1, 3)
------------------------------
[[[1]
[2]
[3]]
[[4]
[5]
[6]]]
(2, 3, 1)
▶ ndarray.astype()
- 배열의 데이터 타입을 변경한다.
a = np.array([1, 2, 3])
print(a) # [1 2 3]
print(a.dtype) # int32
a_float = a.astype(np.float32)
print(a_float) # [1. 2. 3.]
print(a_float.dtype) # float32
▶ np.squeeze()
- 차원을 축소시켜준다.
a = np.array([[[0], [1], [2]]])
print(a)
print(a.shape) # (1, 3, 1)
print('-'*30)
# 3차원 배열을 1차원 벡터로 축소
b = np.squeeze(a)
print(b)
print(b.shape) # (3,)
print('-'*30)
# 3차원 배열의 깊이 축을 축소
c = np.squeeze(a, axis=0)
print(c)
print(c.shape) # (3, 1)
print('-'*30)
# 3차원 배열의 행 축을 축소
# 원본의 원소 개수와 일치 되지 않으면 에러 발생
# d = np.squeeze(a, axis=1)
# 2차원 배열
x = np.array([[1234]])
print(x)
print(x.shape) # (1, 1)
print('-'*30)
# 단일 값 (스칼라 값)으로 변경
y = np.squeeze(x)
print(y)
print(y.shape)[[[0]
[1]
[2]]]
(1, 3, 1)
------------------------------
[0 1 2]
(3,)
------------------------------
[[0]
[1]
[2]]
(3, 1)
------------------------------
[[1234]]
(1, 1)
------------------------------
1234
()
▶ np.concatenate()
- 두 개 이상의 배열을 연결한다.
- 연결을 수행하려면 차원의 수가 같아야 한다.
a = np.arange(1, 5).reshape(2, 2)
print(a)
print('-'*30)
b = np.array([5, 6])
print(b)
print('-'*30)
# 차원 수가 다르기 때문에 에러 발생
# print(np.concatenate((a,b)))
# a와 b를 연결하려면 b의 차원을 1차원에서 2차원으로 늘려야 함
# (2,) -> (1, 2)로 변경이 되어야 하므로 axis=0으로 지정
print(np.concatenate((a, np.expand_dims(b, axis=0))))[[1 2]
[3 4]]
------------------------------
[5 6]
------------------------------
[[1 2]
[3 4]
[5 6]]
# 세 개 이상의 배열을 연결할 수도 있다.
b = np.array([[5, 6]])
c = np.array([[7, 8]])
d = np.concatenate((a,b,c))
print(d)[[1 2]
[3 4]
[5 6]
[7 8]]
- axis 인수를 설정하면 연결 방향을 정할 수 있다. (기본 값 : axis=0)
- 행을 기준으로 연결을 할 때에는 열의 개수가 일치해야 하고
- 열을 기준으로 연결을 할 때에는 행의 개수가 일치해야 한다
# b.T는 행렬 b를 행과 열의 방향을 바꾼다 (전치)
e = np.concatenate((a,b.T), axis=1)
print(e)[[1 2 5]
[3 4 6]]