[ML] 지도학습 알고리즘 - 분류분석, 다항 로지스틱 회귀분석
■ 분류 분석(Classification Analysis)
* 정의
- 종속변수가 범주형인 데이터에 대해 데이터의 유사성(특이성이 비슷한)이 높은 것들을 같은 종류로 분류가 되도록 하는 분석방법
* 용도
- 종속변수가 미리 결정된 범주 중 하나에 속할 가능성 또는 확률을 예측
- 미래 데이터 세트에서 동일한 패턴(유사한 시퀀스, 단어 또는 감정)을 찾고자 할 때 사용
- 이메일 스펨 분류, 고객의 유형 분류 등 종속변수가 범주형 값을 갖는 데이터를 예측하는데 주로 활용
* 종류
- 로지스틱 회귀분석 : 종속변수가 범주형 변수일 때 사용하는 회귀분석
- 의사결정트리 : 나무 형태의 그래프로 의사 결정을 표현하여 데이터를 분류하는 알고리즘
- 나이브베이즈 : 데이터 집합의 예측 변수가 독립적으로 가정하는 분류 알고리즘
- K-Nearest Neighbors : 데이터 포인터 간의 거리를 기반으로 데이터를 분류 및 예측하는 알고리즘
▶ 로지스틱 회귀분석(Logistic Regression)
- 종속변수가 범주형 변수일 때 입력 변수를 기반으로 결과를 예측하기 위한 분석 방법
- 회귀식을 이용하여 새로운 값에 대한 분류를 하지만 목표변수가 범주형 변수인 경우에 사용한다는 점에서 일반 회귀분석과 차이가 있음
- 이진분류 문제를 풀기 위한 대표적인 알고리즘

- P(Y = 1|X = x) 계산
- 임계값(Cut-ff value) 결정
- P(Y = 1|X = x)가 임계값 보다 큰 경우 1로, 작은 경우 0으로 분류

- 데이터를 두 개의 그룹으로 분류하는 문제에서 로지스틱 회귀분석이 일반 회귀분석과의 차이는 회귀분석에서 종속변수(y)의 결과는 실수이지만 로지스틱 회귀분석에서는 종속변수 값이 0 또는 1을 갖는다.
- 따라서, 이진분류 문제에서는 선형함수를 사용할 수 없다.

- 다른 x값에 비해 큰 x=20으로 인해서 선형함수의 기울기가 더 작아지고 새로운 데이터의 추가로 인해서 기존에 잘 분류되었던 (9,1)과 (10,1)을 분류하는데 실패하게 된다. 즉, 새로운 데이터의 추가가 기존의 분류 모델에 큰 영향을 미치게 된다.
- 비선형 모델
- 지수함수를 활용한 회귀분석
- 확률밀도함수(Probability Density Function), 출력결과: 0 ~ 1



■ 다항 로지스틱 회귀분석 (Multiclass Logistic Regression)
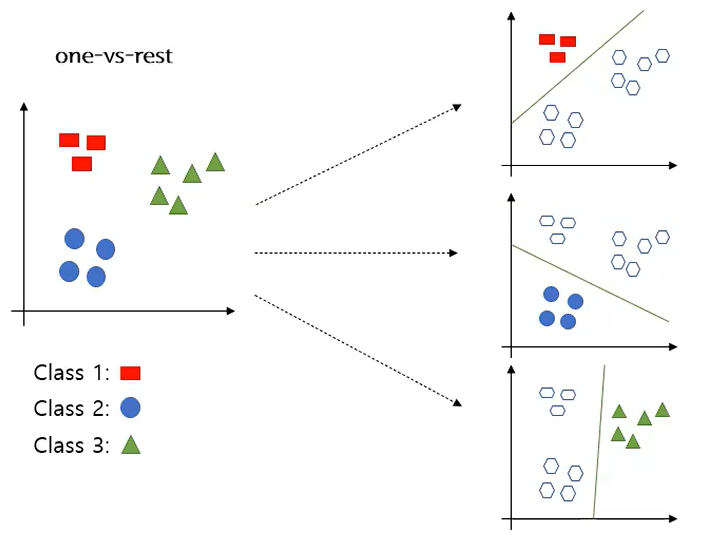

* one-vs-rest : 멀티 클래스 분류 문제를 이진분류 문제로 치환헤서 처리, 학습에 전체 데이터 사용
* one-vs-one : 1:1로만 대응, 각 분류기의 학습에 전체 데이터 중 현재 구별 대상이 되는 두 클래스의 데이터만 사용