데이터 분석/머신러닝
[ML] 비지도학습 알고리즘 - 군집분석
eunnys
2023. 11. 23. 18:00
■ K-평균 군집 (K-Means Clustering)
- 군집 (Clustering)
- 데이터를 여러 개의 군집으로 묶는 분석 방법
- 유사한 개체들을 군집으로 그룹화하여 각 집단의 성격을 파악
- 같은 군집에 속하는 데이터는 다른 군집에 속하는 데이터들보다 유사성이 높다

- 주어진 데이터를 k개의 군집으로 묶는 알고리즘으로, means는 각 데이터로부터 그 데이터가 속한 클러스터의 중심까지의 평균 거리이고 이 값을 최소화하는 것이 알고리즘의 목표
- 데이터가 연속형일 때 사용한다 (명목형 데이터는 직선 거리를 구할 수 없기 때문)
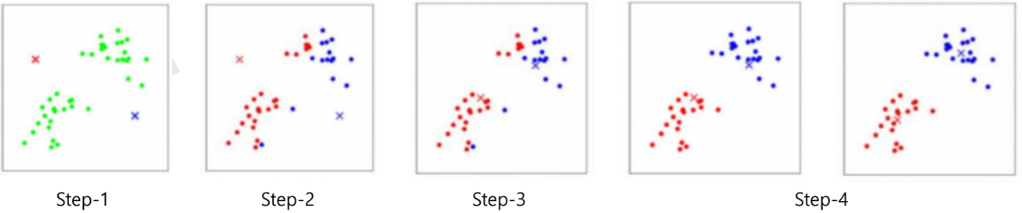
- 군집 수행 과정
- Step-1 : k개의 임의의 중심점(centroid)을 배치, 각 데이터들에 대해 중심점과의 거리 계산 (유클리드 거리)
- Step-2 : 모든 데이터를 가장 가까운 군집 중심에 할당
- Step-3 : 각 군집에 포함된 데이터들의 평균값으로 새로운 군집 중심으로 재설정
- Step-4 : 군집 중심의 변화가 거의 없을 때까지 Step-2와 Step-3을 반복
- KMeans 클래스 생성자 주요 속성

- KMeans 군집화 수행 완료 후 주요 속성

- 최적의 K?
- K값을 늘려가면서 최적의 군집을 찾아내는 방법. 어떤 K가 적절한지에 대한 명확한 답은 없다.
- K값에 따른 군집내 응집도(각 데이터에서 할당된 클러스터의 중심까지의 제곱 거리 합계)를 보고 최적의 K를 선택하는 방법.
- 군집의 수에 따라 응집도가 완만하게 줄어드는 곳을 기점으로 군집의 수를 정한다.

■ 군집평가
- 군집의 대상이 되는 데이터는 타깃 레이블을 가지고 있지 않는 것이 일반적이다. 따라서 분류와 유사해 보일 수 있으나 분류 값 데이터(라벨)을 가지고 있지 않기 때문에 데이터 내에 숨어 있는 특성을 통해 동일한 분류로 구분하는데 있어 그 차이가 있다.
- 군집은 비지도학습의 특성상 어떠한 지표라도 정확하게 성능을 측정하기 어렵다.
- 군집화의 성능을 평가하는 대표적인 방법으로 실루엣 분석이라는 것을 이용한다.
■ 실루엣 분석 (Silhouette Analysis)
- 실루엣 분석은 두 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지를 나타낸다.
- 효율적 분리란 다른 군집과의 거리는 멀리 떨어져 있고, 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐져 있다는 것을 의미한다.
- 실루엣 분석은 실루엣 계수를 기반으로 하며, 개별 데이터가 가지는 군집화 지표이다,

- s(o) : 데이터 포인트 o의 실루엣 계수
- a(o) : o와 o가 속한 클러스터의 다른 모든 데이터 포인트 사이의 평균거리
- b(o) : o에서부터 o가 속하지 않은 모든 군집 중 가장 가까운 군집과의 평균거리
- max(a(o), b(o)) : 두 군집 간의 거리 값(b(o) - a(o))을 정규화하기 위함
- 실루엣 계수는 [-1,1] 사이의 값을 갖고, 1은 데이터 포인트 o가 자신이 속해 있는 클러스터에 딱 맞아 떨어지며 다른 클러스터와는 멀리 떨어져 있다는 의미이며, 0에 가까울수록 근처의 군집과 가까워진다는 의미다. -값은 다른 군집에 데이터 포인트가 할당됐음을 의미한다.


- x축 : 실루엣 계수
- y축 : 개별 군집에 이에 속하는 데이터 (y축의 높이가 해당 군집에 속해있는 데이터 수를 의미)
- 점선 : 전체 평균 실루엣 계수 값