■ Pandas 개요
- pandas는 데이터 조작 및 분석을 위해 파이썬 프로그래밍 언어로 작성된 소프트웨어 라이브러리이다.
- 일명 파이썬의 엑셀이라 부른다.
- URL : https://pandas.pydata.org
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
■ Pandas 불러오기
-pandas는 일반적으로 pd라는 별칭으로 불러온다.
import pandas as pd
import numpy as np
■ Pandas에서 사용하는 자료 구조
**pandas의 구성 요소**
(1) Series
- DataFrame 중에서 하나의 column에 해당하는 데이터
- 1차원 데이터 (index, values 2가지 요소로 구성)
(2) DataFrame
- Data Table 전체를 의미하는 데이터
- 2차원 데이터 (index, values, columns 3가지 요소로 구성)
(3) Index
- Series, DataFrame의 인덱스를 구성하는 데이터


▶ 시리즈(Series)
- 인덱스 값을 명시적으로 지정하지 않으면 0부터 시작하는 일련번호로 자동 지정된다.

nums = [2,3,5,7,9]
sr = pd.Series(nums)
print(sr)
print(type(sr))0 2
1 3
2 5
3 7
4 9
dtype: int64
<class 'pandas.core.series.Series'>
- 인덱스를 직접 지정할 수도 있다.
sr = pd.Series(nums, index=list('abcde'))
print(sr)
print('-'*20)
menu_list = ['토스트', '제육볶음', '치킨']
index_list = ['아침', '점심', '저녁']
sr = pd.Series(menu_list, index=index_list)
print(sr)a 2
b 3
c 5
d 7
e 9
dtype: int64
--------------------
아침 토스트
점심 제육볶음
저녁 치킨
dtype: object# 넘파이의 다차원 배열 형태로 반환
print(sr.index.values)
print(sr.values)['아침' '점심' '저녁']
['토스트' '제육볶음' '치킨']
- 딕셔너리를 이용해서 series 생성하기
dic_data = {'a':21, 'b':22, 'c':23, 'd':24, 'e':25}
sr = pd.Series(dic_data, dtype=np.float32)
print(sr)a 21.0
b 22.0
c 23.0
d 24.0
e 25.0
dtype: float32▶ 원소 선택
print(sr[0]) # 인덱스 값으로 가져오기
print(sr['a']) # 인덱스 이름으로 가져오기
print(sr['a':'c']) # 이름으로 가져올 땐 마지막 요소 포함
print(sr[0:3]) # 인덱스 값으로 가져올 땐 마지막 요소 포함하지 않음21.0
21.0
a 21.0
b 22.0
c 23.0
dtype: float32
a 21.0
b 22.0
c 23.0
dtype: float32▶ unique(), value_counts()
- unique() : 결측치를 포함하며 중복된 데이터를 제외한 데이터의 종류를 ndarray로 반환한다.
- value_counts() : 결측치를 포함하지 않으며 데이터 종류의 개수를 series로 반환한다.
sr = pd.Series(['A', 'B', 'A', np.NaN, 'C', 'D', 'D', 'A'])
print(sr.unique())
print(sr.value_counts())['A' 'B' nan 'C' 'D']
A 3
D 2
B 1
C 1
Name: count, dtype: int64▶ 데이터프레임(DataFrame)



print(df.index)
print(df.columns)
print(df.values)Index(['아침', '점심', '저녁'], dtype='object')
Index(['월', '화', '수'], dtype='object')
[['토스트' '시리얼' '스크램블']
['제육볶음' '칼국수' '육개장']
['치킨' '삼겹살' '라면']]
- 딕셔너리를 이용한 데이터프레임 생성
data = {
'이름':['홍길동','전우치','손오공','사오정','저팔계'],
'나이':[32, 27, 30, 31, 33],
'전화번호':['010-111-1111','010-222-2222','010-333-3333','010-444-4444','010-555-5555']
}
df = pd.DataFrame(data, index=np.arange(1, 6))
display(df)
■ 데이터 조회 및 처리
import numpy as np
import pandas as pd
data = np.random.randint(100, size=(10,10)) # 0이상 100미만의 10행10열의 정수 난수 발생
df = pd.DataFrame(data, index=list('abcdefghij'), columns=list('ABCDEFGHIJ'))
display(df)
▶ 데이터 조회
○ 열의 값 읽기
- df[열명] / df.열명
print(df.A) # A컬럼의 값을 시리즈로 반환
print(df['A'])a 10
b 85
c 28
d 72
e 80
f 78
g 51
h 55
i 33
j 77
Name: A, dtype: int32# 여러 개의 열 값 읽기
print(df[['A', 'B']]) # 리스트의 형태로 전달하면 데이터 프레임으로 반환 A B
a 10 95
b 85 49
c 28 6
d 72 35
e 80 82
f 78 35
g 51 12
h 55 80
i 33 19
j 77 27
○ 행의 값 읽기
- df.loc[행명]
df.loc['a']A 10
B 95
C 61
D 32
E 7
F 45
G 74
H 81
I 60
J 12
Name: a, dtype: int32# 여러 개의 행 값 읽기
df.loc[['a','c','e']]
○ df.head(), df.tail()
- 상위(또는 하위) n개의 행을 선택한다.
- 숫자를 지정하지 않으면 기본값으로 5개의 행을 선택한다.

○ df.sample()
- n개의 랜덤 데이터 추출

▶ 데이터프레임 정보 조회
○ df.dtypes
- 컬럼별 데이터 타입 조회
print(df.dtypes)A int32
B int32
C int32
D int32
E int32
F int32
G int32
H int32
I int32
J int32
dtype: object
○ df.shape
- 데이터프레임의 모양 확인
print(df.shape) # (10, 10)
○ df.count()
- 데이터의 열마다 non-NA 레코드의 개수를 시리즈 형태로 반환
df.count() # 결측치는 포함하지 않음A 10
B 10
C 10
D 10
E 10
F 10
G 10
H 10
I 10
J 10
dtype: int64
○ df.describe()
- 데이터프레임의 기술 통계 정보 요약
print(df.describe()) A B C D E F \
count 10.000000 10.000000 10.000000 10.000000 10.000000 10.000000
mean 56.900000 44.000000 53.200000 45.900000 58.300000 55.400000
std 25.916318 31.464265 24.580028 26.421582 34.172926 28.347839
min 10.000000 6.000000 12.000000 13.000000 7.000000 17.000000
25% 37.500000 21.000000 33.750000 29.000000 32.000000 35.000000
50% 63.500000 35.000000 61.500000 43.000000 66.000000 45.500000
75% 77.750000 72.250000 63.750000 54.750000 86.500000 81.500000
max 85.000000 95.000000 91.000000 89.000000 97.000000 95.000000
G H I J
count 10.000000 10.00000 10.000000 10.000000
mean 63.000000 52.30000 63.400000 35.700000
std 28.538473 26.52902 16.063762 25.412377
min 17.000000 21.00000 41.000000 3.000000
25% 39.500000 31.00000 53.000000 15.000000
50% 73.500000 47.00000 61.000000 32.500000
75% 83.500000 76.75000 75.500000 47.750000
max 93.000000 94.00000 86.000000 77.000000
○ df.info()
- 데이터프레임의 각 컬럼의 타입 및 non-null count의 개수 확인
print(df.info())<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, a to j
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 10 non-null int32
1 B 10 non-null int32
2 C 10 non-null int32
3 D 10 non-null int32
4 E 10 non-null int32
5 F 10 non-null int32
6 G 10 non-null int32
7 H 10 non-null int32
8 I 10 non-null int32
9 J 10 non-null int32
dtypes: int32(10)
memory usage: 780.0+ bytes
None▶ 인덱싱, 슬라이싱
df[['A','C']]
- 열의 순서를 이용해서 인덱싱을 할 수 없다.
# df[0] 에러 발생
- 열 위치 값을 이용해서 인덱싱이나 슬라이싱을 이용하려면 columns 속성을 이용한다.
df.columns # 컬럼의 값을 ndarray로 반환
# Index(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
df.columns[0] # 위치 값을 이용해서 컬럼명을 가져올 수 있다
# 'A'df[df.columns[2:4]]
- 행의 이름을 이용해서 슬라이싱을 할 수 있다.
- 마지막 요소까지 범위에 포함된다,
# df['a':'c'] 동일한 결과
# 행단위 추출은 loc 속성을 이용한다
df.loc['a':'c']
- 행의 순서를 이용해서 슬라이싱을 할 수 있다.
- df.iloc 속성 사용
df.iloc[2:5]
▶ 특정 위치의 데이터 추출
○ df.at, df.iat
- 라벨 또는 인덱스를 이용해서 특정 위치의 데이터를 가져온다. (단일값 추출)
df.at['c','E'] # c행E열df.iat[4,4] # 위치 값
○ df.loc, df.iloc
- 행과 열의 라벨 또는 인덱스를 이용해서 특정 위치의 데이터를 조회한다.
df.loc[['e','a','c'], ['C','C','A']]
df.iloc[0:5:2, 5:10:2] # (시작:끝:스텝)
▶ 조건 인덱싱
# 데이터프레임의 A열의 요소 중 50을 초과하는 값이 있을 때 해당 값의 행을 선택
df[df['A'] > 50]
# 데이터프레임의 b행의 요소 중 50을 초과하는 값이 있을 때 해당 값의 열을 선택
df.loc[:, df.loc['b'] > 50]
df[df % 2 == 0] # 짝수 값만 표시
df2 = df.copy()
# 새로운 컬럼 추가
df2['K'] = ['one','two','one','two','one','two','one','two','one','two']
df2
# K컬럼의 one이 포함된 값만 가져오기
df2['K'].isin(['one']) # 마스킹 값a True
b False
c True
d False
e True
f False
g True
h False
i True
j False
Name: K, dtype: bool# 마스킹 값을 인덱스 값으로 넣어줌
df2[df2['K'].isin(['one'])]
# 특정 값을 포함하지 않는 레코드 검색 : ~ 연산자 사용
df2[~df2['K'].isin(['one'])]
▶ 데이터 수정
df['E'] = 0
df
# 특정 요소 삭제하기
df.drop('E', axis=0, inplace=True)df.at['e','E'] = 1
df
df.loc['d':'f'] = 0
df
np.random.seed(0)
df = pd.DataFrame(np.random.randint(100, size=(10,10)),
index=list('abcdefghij'), columns=list('ABCDEFGHIJ'))
display(df)
▶ 데이터 정렬
○ df.sort_values()
- 행 또는 열을 지정해서 값에 따라 정렬한다.
- 기본 값은 열을 지정해서 값을 따라 오름차순으로 정렬하는 것이다.
- 내림차순으로 정렬하려면 ascending=False
- 행을 지정해서 정렬하려면 axis=1 또는 axis=columns
# A컬럼을 기준으로 오름차순 정렬
df.sort_values('A')
# A컬럼을 기준으로 내림차순 정렬
df.sort_values('A', ascending=False)
# a행을 기준으로 오름차순 정렬
df.sort_values('a', axis=1)
○ df.sort_index()
- 행 또는 열 값을 기준으로 정렬한다.
- 기본값은 인덱스(행)를 오름차순으로 정렬하는 것이다.
- 컬럼명에 따라 정렬하려면 axis=1
# 행 기준 내림차순
df.sort_index(ascending=False)
# 컬럼명을 기준으로 내림차순 정렬
df.sort_index(axis=1, ascending=False)
■ 데이터프레임 조작
▶ 새로운 행 또는 열 추가
○ DataFrame에 새로운 열 추가
- df.[새로운 컬럼명] = 데이터 목록
- 데이터의 목록은 Dataframe내 다른 컬럼들의 원소와 같은 개수이어야 한다.
- 데이터 목록 타입 : list, Series, ndarray
○ DataFrame에 새로운 행 추가
- df.loc[새로운 행이름] = 데이터 목록
- 데이터 목록은 기존 DataFrame의 컬럼의 개수와 `타입`이 같아야 한다.
import numpy as np
import pandas as pd
df = pd.DataFrame([[1,2,3],[7,8,9],[13,14,15]],
index=list('ABC'), columns=list('abc'))
df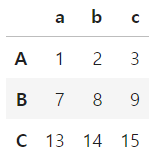
# 새로운 행 추가
df.loc['D'] = [19,20,21]
df
# 새로운 열 추가
df['d'] = [4,10,16,22]
df
○ Series를 이용해서 새로운 행 또는 열 추가
- 시리즈 객체를 이용해서 새로운 행 또는 열을 추가할 때는 **기존 데이터프레임과 같은 인덱스를 갖도록** 작성한다.
- 인덱스를 정확하게 명시하지 않으면 추가되는 요소는 NaN으로 초기화 된다.
# 인덱스를 명시하지 않을 경우
df2 = df.copy()
df2.loc['F'] = pd.Series([31,32,33,34])
df2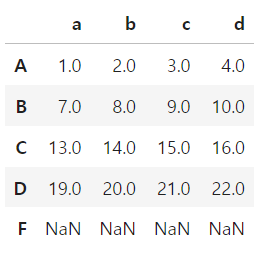
df.loc['F'] = pd.Series([31,32,33,34], index=df.columns)
df
○ 임의의 위치에 열 삽입
- df.insert(위치, 컬럼명, 값)
df.insert(1, 'K', [1,1,1,1,1])
df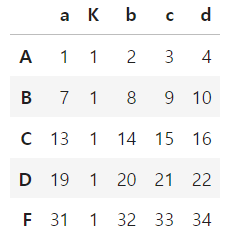
▶ 행과 열의 변경
df = pd.DataFrame(np.arange(1,10).reshape(3,3), columns=list('abc')) # 컬럼은 자동생성
df
○ df.reindex()
- 새로운 행 또는 열을 추가한다.
- 추가되는 행 또는 열의 요소는 NaN으로 초기화 된다. (fill_value 매개변수를 통해 특정 값으로 초기화 할 수 있다)
- 실행 결과는 원본에 영향을 주지 않고 **새로운 데이터프레임 객체를 반환**한다.
# 익덱스의 구조를 재정의 ([0,1,2] -> [0,1,2,3], (a,b,c) -> (a,b,c,d), NaN은 0으로 채움)
# 원본엔 영향을 주지 않음
df.reindex(index=[0,1,2,3], columns=list('abcd'), fill_value=0)
- 행 또는 열의 순서를 임의로 섞을 수도 있다.
- 기존에 존재하던 라벨을 생략해서 행 또는 열을 삭제할 수도 있다.
# 행을 삭제하고 순서 섞기
df.reindex(index=[0,1], columns=['b','a','b'])
○ df.set_index()
- 열을 인덱스로 만든다.
- df.set_index(열이름, inplace=True), inplace=True : 원본을 변경하는 속성

# a컬럼의 값을 인덱스화
df.set_index('a', inplace=True)
○ df.reset_index()
- 인덱스를 열 데이터로 추가한다.
- 인덱스 초기화 : drop=True 인수를 전달하면 기존 인덱스를 삭제하고 기본값으로 다시 초기화 한다.
# 인덱스화 했던 a컬럼을 다시 컬럼으로 추가
df.reset_index()
# 인덱스화 했던 a컬럼 삭제
df.reset_index(drop=True)
▶ 행과 열의 삭제
- 실행 결과는 원본에 영향을 주지 않고 새로운 데이터프레임을 반환한다. (inplace=False가 기본값)
<열 제거>
- del df[컬럼명]
- df.drop(컬럼명 목록, axis=1) : 리스트의 형태로 전달해서 여러 개의 컬럼을 동시에 삭제할 수도 있다.
- df.drop(columns=컬럼명 목록) : 명확하게 컬럼을 삭제하겠다는 의미이기 때문에 별도의 축 옵션은 필요 없다.
<행 제거>
- df.drop(행이름 목록) : 기본값인 axis=0 생략 가능
- df.drop(rows=행이름 목록) : 명확하게 행을 삭제하겠다는 의미이기 때문에 별도의 축 옵션은 필요 없다.
df = pd.DataFrame([[1,2],[3,4]], index=['A','B'], columns=['a','b'])
df
# df.drop('a') 에러 발생 (행 삭제로 인지, a행은 존재하지 않음)df.drop('A') # 행 삭제
df.drop('a', axis=1) # 열 삭제
▶ 행과 열의 이름 바꾸기
df = pd.DataFrame(np.random.randint(1, 100, size=(4,4)))
df
# 새로운 컬럼명을 넣어줌
df.columns = ['C1','C2','C3','C4']
# 새로운 인덱스를 넣어줌
df.index = list('abcd')
df
○ 특정 행 또는 열의 이름만 바꾸기
- df.rename(index=dictionary 객체)
- df.rename(columns=dictionary 객체)
# key 값은 기존 인덱스, value 값은 새로운 인덱스
df.rename(index={'a':'A'}, inplace=True)
df.rename(columns={'C1':'국어'}, inplace=True)
df
○ 컬럼 이름의 특정 문자 바꾸기
df.index = list('ABCD')
df.columns = ['1기 A반', '1기 B반', '2기 A반', '2기 B반']
df
- str 모듈은 문자열을 다루는 함수를 가지고 있다.
# str 모듈을 사용해 컬럼명의 공백을 언더스코어로 바꾸기
df.columns = df.columns.str.replace(' ','_')
df
○ 컬럼명에 접두사 밑 접미사 붙이기
- df.add_prefix() 접두사
- df.add_suffix() 접미사
df = df.add_prefix('KDM')
df
▶ 데이터프레임 간의 조합
df = pd.DataFrame([[1,2],[3,4]], index=['A','B'], columns=['a','b'])
df
○ pd.concat
- 두 개 이상의 데이터프레임을 행 또는 열 방향으로 연결한다.
- 열 방향으로 연결하고자 할 경우 axis=1 인자를 전달한다. (기본값은 axis=0)
- 행 방향으로 연결하고자 할 때는 열 이름이 같아야 하고
- 열 방향으로 연결하고자 할 때는 행 이름이 같아야 한다.
# 똑같은 데이터프레임을 행 방향으로 연결
df2 = pd.concat([df,df])
df2
# 열 방향으로 연결
df3 = pd.concat([df, df], axis=1)
df3
■ 집계함수
- 모든 집계함수는 axis=0을 기본값으로 한다. (열 기준으로 집계)
- df.mean() : 각 행과 열에 대한 평균을 산출한다.
- df.std() : 각 행과 열에 대한 표준편자를 산출한다.
- df.min() / df.max() : 각 행과 열에 대한 최소 / 최대값를 산출한다.
[문제] Series, DataFrame 생성 및 연산
- (1) 각 컬럼 값은 Series 객체로 생성
- (2) 앞서 만든 Series 객체를 이용해서 DataFrame 생성
- (3) 각 과목의 합계를 계산한 컬럼 추가
- (4) 각 과목의 평균을 계산한 컬럼 추가
index_list = ['홍길동','임꺽정','전우치','손오공','저팔계','사오정']
sr_major = pd.Series(['컴퓨터공학과','수학과','정보통신학과','수학과','컴퓨터공학과','컴퓨터공학과'], index=index_list)
sr_math = pd.Series([97,88,91,76,88,87], index=index_list)
sr_kor = pd.Series([88,89,85,90,88,77], index=index_list)
sr_eng = pd.Series([90,100,96,91,80,90], index=index_list)score_df = pd.DataFrame({'전공':sr_major, '수학':sr_math, '국어':sr_kor, '영어':sr_eng})
score_df
score_df.shape # (6, 4)
score_df.head()
score_df.info()
score_df.describe() # 수치형 데이터만 보여줌
score_df.describe(include=object) # 명목형 데이터만 보여줌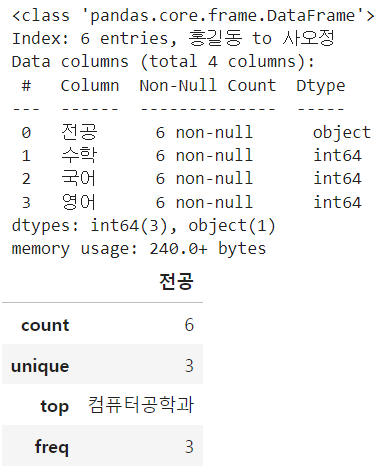
score_df.loc['임꺽정':'손오공'] # 행 슬라이싱
# 합계 컬럼 추가(loc 사용)
score_df['합계'] = score_df.loc[:,'수학':'영어'].sum(axis=1)
score_df
score_df.drop('합계', axis=1, inplace=True)score_df
# 합계 컬럼 추가(loc를 사용하지 않고, 복수의 컬럼 목록 가져오기)
score_df['합계'] = score_df[['수학','국어','영어']].sum(axis=1)# 평균 컬럼 추가
score_df['평균'] = score_df.loc[:,'수학':'영어'].mean(axis=1)
score_df
# 평균 값 포맷 적용하기 (소수점 이하 2자리)
# 시리즈 객체에 apply함수 적용(x에는 평균 컬럼에 있는 값들이 하나씩 들어옴)
score_df['평균'] = score_df['평균'].apply(lambda x: f'{x:.2f}')score_df
# 평균값이 object 타입으로 바뀜
score_df.info()<class 'pandas.core.frame.DataFrame'>
Index: 6 entries, 홍길동 to 사오정
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 전공 6 non-null object
1 수학 6 non-null int64
2 국어 6 non-null int64
3 영어 6 non-null int64
4 합계 6 non-null int64
5 평균 6 non-null object
dtypes: int64(4), object(2)
memory usage: 508.0+ bytes# 평균 값을 다시 수치형으로 바꿔줌
score_df['평균'] = score_df['평균'].astype(float)score_df.info()<class 'pandas.core.frame.DataFrame'>
Index: 6 entries, 홍길동 to 사오정
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 전공 6 non-null object
1 수학 6 non-null int64
2 국어 6 non-null int64
3 영어 6 non-null int64
4 합계 6 non-null int64
5 평균 6 non-null float64
dtypes: float64(1), int64(4), object(1)
memory usage: 508.0+ bytes■ 결측값 처리
import numpy as np
import pandas as pd
data = np.random.randint(0, 10, (5,5))
df = pd.DataFrame(data, index=list('ABCDE'), columns=list('abcde'))
df
# 결측값 설정
df.at['B','c'] = np.nan # B행c열
df.at['D','e'] = np.nan # D행e열
df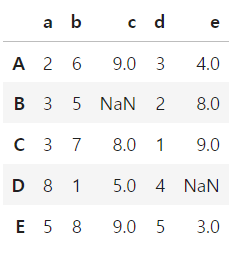
○ df.isna(), df.notna()
- 데이터가 NaN인지 아닌지 검사
- 결과는 True/False로 반환
checked_nan = df.isna()
print(checked_nan) a b c d e
A False False False False False
B False False True False False
C False False False False False
D False False False False True
E False False False False False# 각 컬럼별 True값 집계
print(checked_nan.sum())a 0
b 0
c 1
d 0
e 1
dtype: int64
○ df.dropna()
- 결측값을 포함한 행 또는 열을 삭제
- 기본값은 결측값이 존재하는 행을 모두 삭제하는 방식
df.dropna()
- axis=1 인수를 설정하면 결측값이 있는 열을 제거할 수 있다.
df.dropna(axis=1)
- subset 인수를 설정하면 모든 컬럼이 아닌 특정 컬럼의 결측값 데이터만 삭제
# c컬럼에 결측값이 있는 행을 제거
df.dropna(subset=['c'])
○ df.fillna()
- 결측값을 다른 값으로 채운다.
# 모든 결측치에 대해 적용
df.fillna(-999)
# 특정 컬럼의 평균값 넣기
df['c'] = df['c'].fillna(df['c'].mean())
df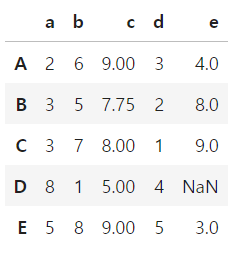
- method 인자를 사용하면 열 기준 바로 앞 또는 뒤에 있는 값으로 채운다.
- method='pad' or method='ffill' : 앞의 값으로 채움
- method='backfill' or method='bfill' : 뒤의 값으로 채움
# D행e열의 NaN값을 앞의 값(C행e열)으로 채움
df.fillna(method='pad')
# D행e열의 NaN값을 뒤의 값(E행e열)으로 채움
df.fillna(method='bfill')
■ 데이터 중복 제거
df = pd.DataFrame({'k1':['one','two']*3+['two'],
'k2':[1, 1, 2, 3, 3, 4, 4]})
df
▶ 중복 데이터 검사
- df.duplicated() : 각 행의 중복 여부를 검사하여 결과를 True/False로 반환
df.duplicated() # 5번과 6번 레코드 중복0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
▶ 중복 데이터 삭제
- df.drop_duplicates() : 모든 컬럼에 대해 중복 값을 갖는 행을 제거
df.drop_duplicates()
▶ 지정된 컬럼의 중복 데이터 삭제
- df.drop_duplicates(컬럼명 목록) : 매개변수로 주어진 컬럼별 목록에 대해 같은 값을 갖는 행을 제거
df['k3'] = np.arange(7)
df
df.drop_duplicates(['k1','k2']) # 6번 레코드 삭제
○ keep='last' parameter
- drop_duplicates는 기본적으로 처음 발견된 값을 유지한다.
- keep='last' 옵션을 지정하면 마지막으로 발견된 값을 유지한다.
df.drop_duplicates(['k1','k2'], keep='last') # 5번 레코드 삭제
■ 데이터프레임 재구조화
▶ pd.pivot_table(), df.pivot_table()
- 피벗 테이블 : 기존 데이터를 기반으로 합계나 통계를 산출할 목적으로 새로운 표를 만드는 기능
- df.pivot_table(index=행방향 컬럼, columns=열방향 컬럼, values=집계대상 컬럼, aggfunc=구할 통계값)
df = pd.DataFrame(np.arange(16).reshape(4,4),
index=list('ABCD'), columns=list('abcd'))
year_df = pd.DataFrame([2019, 2020, 2019, 2020],
index=list('ABCD'), columns=['year'])
class_df = pd.DataFrame(list('AABB'),
index=list('ABCD'), columns=['class'])
df = pd.concat([year_df, class_df, df], axis=1)
df
pd.pivot_table(df, index='year', columns='class')
pd.pivot_table(df, index=['year','class']) # 멀티 인덱스
- 중복된 컬럼의 항목은 하나로 합쳐지고 그 값의 평균을 기본 집계 함수로 이용한다.
# 2019년 a열 : 0과 8의 평균 = 4
pd.pivot_table(df, index='year', values=['a','b','c','d'])
# 중복된 컬럼의 합과 평균
pd.pivot_table(df, index='year', values=['a','b','c','d'], aggfunc=[np.sum, np.mean])
[실습] 피벗 테이블 실습
sr_year = pd.Series([2020]*4+[2021]*4+[2022]*4)
sr_quarter = pd.Series(['1Q','2Q','3Q','4Q']*3)
np.random.seed(0)
sr_sales = pd.Series(np.random.randint(500, 6000, 12))
sr_cost = pd.Series(np.random.randint(100, 1200, 12))
df = pd.DataFrame({'year':sr_year,'quarter':sr_quarter, 'sales':sr_sales, 'cost':sr_cost})
df
# 'benefit' 컬럼 추가
df['benefit'] = df['sales'] - df['cost']
df
# 피벗 데이블을 이용하여 연도별 분기 이익 데이터 확인
pd.pivot_table(df, index='year', columns='quarter', values='benefit')
df_pivot = pd.pivot_table(df, index=['year','quarter'], values='benefit')
df_pivot
df_pivot.indexMultiIndex([(2020, '1Q'),
(2020, '2Q'),
(2020, '3Q'),
(2020, '4Q'),
(2021, '1Q'),
(2021, '2Q'),
(2021, '3Q'),
(2021, '4Q'),
(2022, '1Q'),
(2022, '2Q'),
(2022, '3Q'),
(2022, '4Q')],
names=['year', 'quarter'])# 연도별 이익에 대한 평균과 합계
pd.pivot_table(df, index='year', values='benefit', aggfunc=['mean','sum'])
▶ 다중 인덱스
- index, column에 중첩 배열을 전달해서 다중 인덱스를 설정할 수 있다.
df = pd.DataFrame(np.arange(16).reshape(4,4),
index=[[1,2,3,4],['java','python','java','python']],
columns=[['1기','1기','2기','2기'],['오전','오후','오전','오후']])
df
# 1기 데이터 가져오기
df['1기']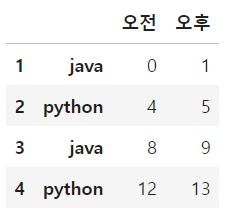
# 1기의 오후 데이터 가져오기
df['1기','오후']1 java 1
2 python 5
3 java 9
4 python 13
Name: (1기, 오후), dtype: int32
# 1행에서 1기에 해당하는 값만 가져오기
df.loc[1, '1기']
■ 그룹핑
- 특정 값을 기준으로 몇 개의 그룹으로 분할하여 처리하는 방식
df = pd.DataFrame({'A':['chol','young']*3+['chol'],
'B':['one','one','two','one','two','two','one'],
'C':np.random.randn(7),
'D':np.random.randn(7)})
df
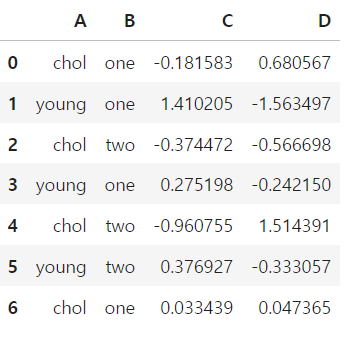
▶ 그룹 객체 만들기
grouped = df.groupby('B')
print(grouped)ㄴ
for key, group in grouped:
print('key:', key)
print(group.head())
print('-'*35)<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000024E27F47B10>
key: one
A B C D
0 chol one -0.181583 0.680567
1 young one 1.410205 -1.563497
3 young one 0.275198 -0.242150
6 chol one 0.033439 0.047365
-----------------------------------
key: two
A B C D
2 chol two -0.374472 -0.566698
4 chol two -0.960755 1.514391
5 young two 0.376927 -0.333057
-----------------------------------# 특정 그룹만 선택
one_group = grouped.get_group('one')
one_group.head()
▶ 그룹 연산
○ 그룹별 통계치 구하기
- df.groupby(컬럼명)[컬럼명 목록].통계함수()
- DataFrame 중 지정한 컬럼들에 대해 그룹별 통계치를 구함
- 통계함수: sum, mean, std, var, min, max, count, quantile 등
df.groupby('B')[['C','D']].sum()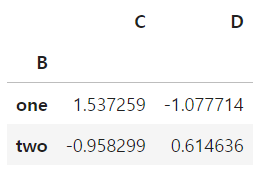
data = pd.read_csv('./sales.csv')
data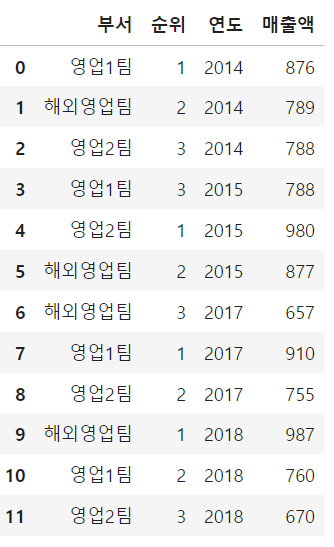
# 부서별 매출액의 합계 (리스트의 형태로 지정하면 데이터프레임으로 반환)
data.groupby('부서')[['매출액']].sum()
# 부서별 연도별 매출액
data.groupby(['부서','연도'])[['매출액']].sum()
data.pivot_table(index=['부서','연도'], values='매출액', aggfunc='sum')
▶ Aggregation
- df.groupby(컬럼명)[컬럼명].agg([통계함수1, 통계함수2, ...])
grouped = data.groupby('부서')# 부서별 최대 매출액과 최소 매출액의 차이 계산 함수
def min_max(x):
return x.max() - x.min()
grouped['매출액'].agg(min_max)부서
영업1팀 150
영업2팀 310
해외영업팀 330
Name: 매출액, dtype: int64grouped['매출액'].agg(['sum','mean','max','min'])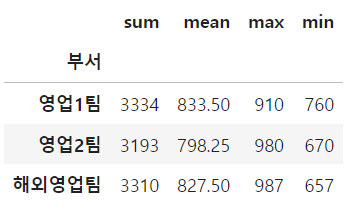
'데이터 분석 > 판다스' 카테고리의 다른 글
| [Pandas] 국가별 알콜 섭취량 데이터 분석 (0) | 2023.11.13 |
|---|---|
| [Pandas] 시애틀 강수량 데이터 분석 (0) | 2023.11.13 |
| [Pandas] DataFrame 합치기 (0) | 2023.11.13 |
| [Pandas] 함수 매핑 (0) | 2023.11.13 |
| [Pandas] 시계열 데이터 (0) | 2023.11.10 |